浅析linux kernel RCU机制
之前在调试Linux Kernel时遇到了一些oops信息是RCU代码中的,看了几天linux kernel的RCU机制,在此记录。
0x01 Linux RCU机制是什么?
RCU全称read only update,是Linux内核中的一种同步机制。RCU的原理可以简述如下:RCU记录了所有对共享数据的使用者。当内核线程需要write某个数据时,先创建一个副本,在副本中修改。当所有读线程都离开临界区后,新的数据才被更新。
相对于其它的同步机制,由于RCU的写时复制,因此如果对于读数据的线程,开销是很小的。只有修改数据时,才会带来额外的开销。
RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。
内核中关于RCU的常见接口如下:
- **rcu_read_lock()/ rcu_read_unlock() ** RCU临界区
- read_newptr = rcu_dereference(ptr) 内核线程读取数据时,获取被RCU保护的指针,进行读操作时,用newptr来读。
- rcu_assign_pointer(ptr, newptr) 修改原来的指针,指向被复制并被修改后的数据。步骤可以简述如下:
- 在写之前,ptr指向旧的数据,创建一个oldptr和newptr,其中oldptr指向原来的数据,newptr需要malloc之后复制时需要的空间。
- 用oldptr复制数据给newptr后,使用newptr更新数据。
- 更新数据完成后,修改原来的指针时,就需要调用本接口rcu_assign_pointer(ptr, newptr) 来实现更新原有的数据。
- 通常在此时候会用4中的回调函数来删除oldptr。
- call_rcu() 注册回调函数,一般是在写的线程中,当所有的读线程离开临界区后,删除旧数据。
0x02 an example to learn linux RCU
例子来源于《奔跑吧linux内核》,详细说明可以参考linux源码中Documentation\RCU\whatisRCU.txt。
在该例子中,我们可以看到上述接口的具体使用说明。通常被rcu保护的struct中会有 struct rcu_head rcu;这个结构体。


在该例子中,需要同步的数据结构为struct foo,并创建了结构体指针g_ptr。
读线程使用rcu_read_lock()/ rcu_read_unlock() 创建临界区后,使用p= rcu_dereference(g_ptr) 来获取被保护的指针,后续使用p来读数据。
写线程创建了old和new_ptr结构体指针,new_ptr调用kmalloc申请了需要复制的结构体的大小,并把old数据复制给new_ptr,之后使用new_ptr修改数据完成后,调用rcu_assign_pointer(g_ptr, new_ptr)来修改原始的g_ptr,并调用call_rcu注册回调函数用户删除old数据。
用一张图片来解释上述过程:

0x03 Tree RCU中的*nxtlist和**nxttail[RCU_NEXT_TAIL]
Linux的RCU机制实现有两种:经典RCU和Tree RCU。RCU机制从linux kernel2.5中开始引入。由于在大型系统中遇到了性能问题,IBM内核专家Paul E. McKenney提出了Tree RCU的实现。
在讲述两种RCU的区别之前,需要明确以下两个概念:宽限期Grace Period(GP)和静止状态Quiescent State(QS)。
宽限期GP,宽限期是一个period,可长可短。参考下图,彩色的部分是一个删除的过程。宽限期从删除动作发生后开始,此时time为t1;t1时所有的读线程都结束后宽限期结束,此时time为t2。GP=t2-t1。因此宽限期可长可短,取决于读线程读多久。
静止状态QS,QS是用来描述CPU的。假设有4个CPU(每个CPU一个thread)对数据进行读操作,当CPU离开临界区后,该CPU就处于静止状态。
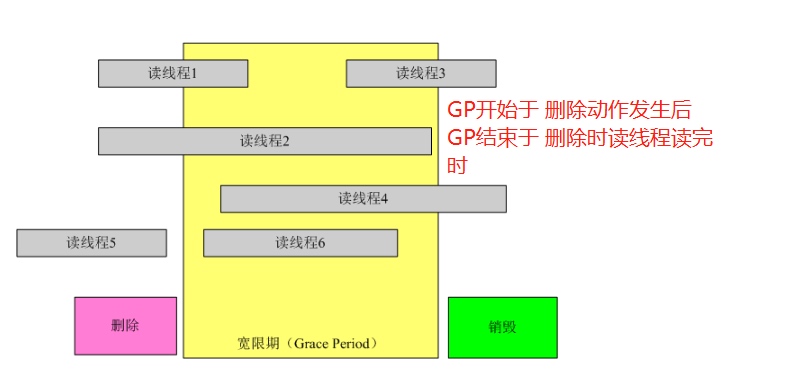
在经典RCU中,使用一个全局的cpumask位图(理解为一个全局变量)来标记所有CPU是否处于QS中。当GP开始时,CPU修改cpumask中的对应位,GP结束时,清楚cpumask中的对应位。由于多个CPU的竞争,需要引入锁的机制。那么当CPU很多时,则竞争的激烈程度成线性增长。
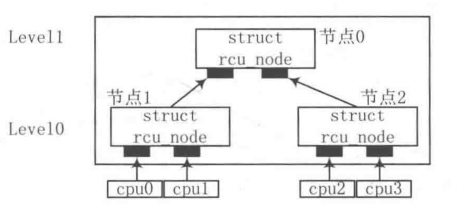
因此,为了解决对cpumask位图的竞争,就引入了Tree RCU。Tree RCU使用rcu_node节点来管理CPU。假设在4核CPU中,一个rcu_node管理2个CPU(假设为CPU1和CPU2),可以用2个rcu_node来管理4个CPU。继续增加一个rcu_node0就可以管理这2个rcu_node,从而管理所有的CPU状态。
当这4个CPU都经历过一个QS后,CPU1和CPU2竞争清除rcu_node1中的对应位,CPU3和CPU4来竞争清除rcu_node2中的对应位。此时,竞争的数量就大大减小了。当rcu_node1和rcu_node2中的对应位都清除后,就可以清除增加的rcu_node0中的对应位。可见Tree RCU的实现就是通过增加rcu_node的方式来减少竞争。实现的过程类似下图中的树形结构:
0x04 rcu_head单链表的增加过程

rcu_head的结构体指针会作为成员出现在RCU机制保护的结构体中,作用是保存写者thread删除old数据时的回调函数(函数作用是删除old数据)。对于该结构体的操作会在call_rcu()中实现。介绍call_rcu()之前需要介绍一下RCU机制中的相关数据结构。
Linux Kernel中在实现Tree RCU中有三个比较重要的数据结构:struct rcu_data、struct rcu_node、struct rcu_state。
- struct rcu_data: 每个CPU一个,可以理解上图中的cpu叶子节点。
- struct rcu_node: 管理rcu_data,可以理解为上图中的rcu_node。
- struct rcu_state:描述不同类型的RCU系统状态的,暂时没用到,先跳过吧。
其中struct rcu_data中具有两个比较重要的成员 struct rcu_head *nxtlist; 和 struct rcu_head **nxttail[RCU_NEXT_SIZE];
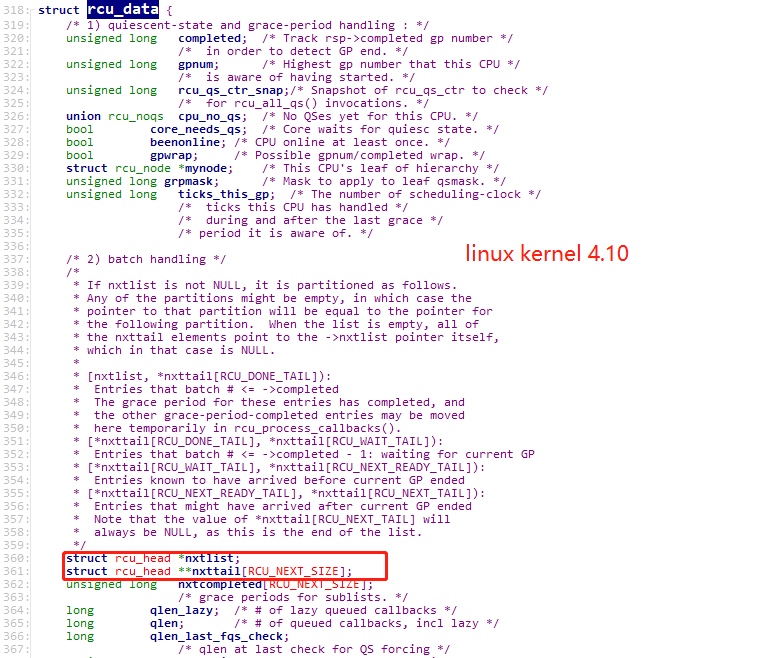
这两个成员实现了对rcu_head的管理。具体如下。
初始化时,nxtlist为NULL,nxttail[RCU_NEXT_TAIL]指向nxlist,保存着nxtlist的地址。
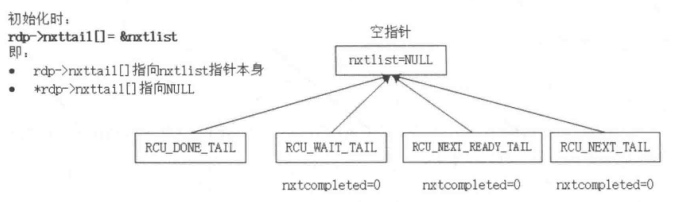
当写者thread调用call_rcu()删除数据时,最终调用__call_rcu()来增加rcu_head结构体链表中的成员。
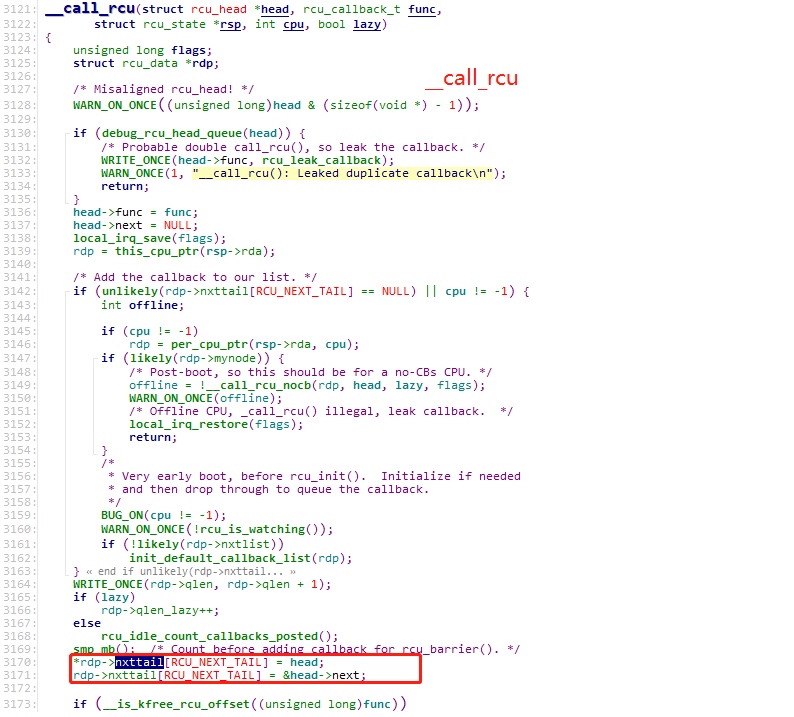
上述代码中,head指向新加入的rcu_head结构体的指针。
-
*rdp->nxttail[RCU_NEXT_TAIL] = head; 起始时,rdp->nxttail[RCU_NEXT_TAIL] 指向nxlist,则nxlist指向了rcu_head,因此此rdp->nxttail[RCU_NEXT_TAIL]总是指向新加入的rcu_head(也就是修改了当前链表中最后一个rcu_head中next为新加入的rcu_head的地址。
-
rdp->nxttail[RCU_NEXT_TAIL] = &head->next; 修改了rdp->nxttail[RCU_NEXT_TAIL] 的内容,指向rcu_head->next,保存存了新加入的rcu_head中next成员的地址,以便后续再加入新的rcu_head。
修改了两个指针的过程如下,对应两个箭头的修改:
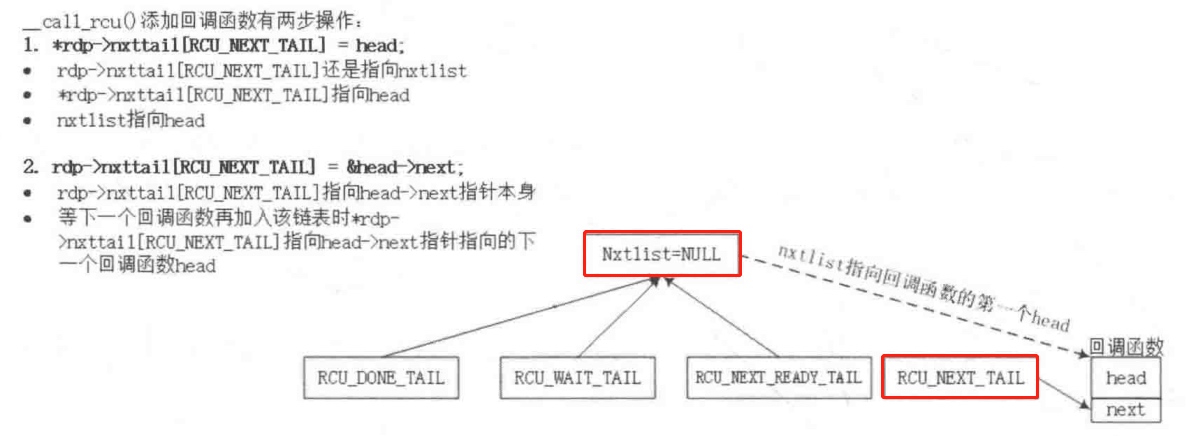
后续再增加new rcu_head时,先修改最后一个rcu_head中的next为new rcu_head的地址,再修改rdp->nxttail[RCU_NEXT_TAIL] 的内容,指向new rcu_head->next。
最终形成了rcu_head单链表,保存着一个GP结束后,需要调用的回调函数。
0x05 参考
- 《奔跑吧Linux内核》
- 《Linux内核设计与实现》
- https://blog.csdn.net/junguo/article/details/8244530
